
Traditionally classification forecasts have been the way sales managers have analyzed and reported on their sales funnel. A classification forecast is produced by categorizing each opportunity in the open funnel as high-, moderate-, or low-probability. These classifications are typically given names such as Commit, Best Case, and Omitted.
In their defense, classification forecasts are great for aligning resources. And classification forecasts are pretty good predictors at the very end of a sales cycle—when you least need it. You typically need good forecasts much earlier.
We've seen hundreds of classification forecasts. All of them exhibit the issues discussed here. For illustration, we use simulations to explore what you can expect from classification forecasts.
First let’s clarify:
We focus on B2B forecasts for new contracted business. We are not considering subscription renewals or forecasts for recognized revenue based on downstream delivery.
B2B forecasts are inherently difficult because so many factors affect whether and when a deal will be won. We have not seen studies of accuracy. Salesforce claims that sales leaders are “accurate within 10% of their forecast the majority (more than 50%) of the time.” It’s an ill-specified figure because it does not say what is being forecasted and how far in advance it was made. In our experience, being within 10% (at the start of the quarter) of the final figure 80% of the time is very good.
Accuracy improves with transaction volume. No one has a reliable forecast for a business with a handful of transactions per quarter.
Accuracy degrades with a wide distribution of transaction values. If a few large deals dominate your business, then it doesn’t matter how good you are at calling wins. If you call the big ones wrong, your forecast will be way off. The best you can hope for is to understand and manage that risk.
How accurate are classification forecasts?
Let's first look at a real classification forecast (Figure 1). This example is typical. The two blue areas are actual sales as they accumulate over the quarter. (The other colored areas are different components of a Funnelcast forecast.) The daily Won + Commit forecast (black line, middle) is conservative until the end of quarter. Won + Commit + Best Case (top purple line) is extremely optimistic. In both cases, until the end of the quarter. What you want is to have the right forecast (like the top of the colored areas) at the start of the quarter. Or the year.
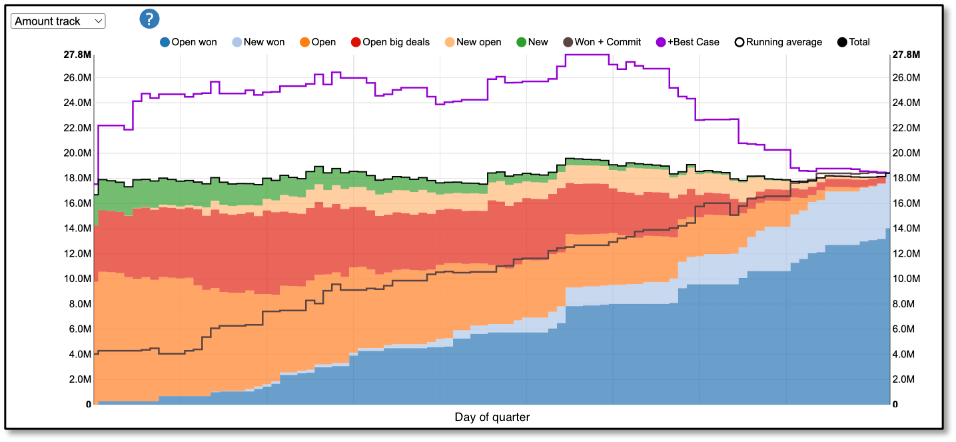
Why don't classification forecasts perform better early in the quarter—like the Funnelcast forecast?
To answer that question, we simulated a two-stage classification (Commit + Best Case) to examine the inherent limitations of these models. Our simulation assumes:
Perfect knowledge of when a deal will resolve as won or lost (upon entering the classification forecast)
No opportunities can be won without being classified in Commit. (No "bluebirds.")
No change in deal value between entering the forecast and closing
No skipping classifications. All opportunities enter in Best Case and (if won) advance to Commit before closing
Consistent rate of opportunities entering the first included category (Best Case).
These are simplifications. Items one and two make the simulation converge on the actual outcome at the end of a quarter; and assure that there is no inappropriate carryover of opportunities to the next one. The other assumptions reduce variance of the simulation compared to the real world. Accordingly, the results here summarize the best that you can expect from classification forecasts. Your results will probably have higher variance due to factors not reflected in the simulation, may not converge at quarter end, and may start too high due to misclassified carryover of opportunities from the previous period.
The simulation is further based on parameters that reflect the nature of the business:
Rate of classifying opportunities in the Best Case
Accuracy of the classifications
Average lead time between entering a classification and closing
Distribution of opportunity values.
The results shown here reflect the specific settings used[1]. The rate of opportunities being added to the forecast and the distribution of deal sizes can have significant effects on forecast variability. More opportunities, similar deal sizes, and more accurate classifications will reduce variability.
In Figure 2 below, we’re showing simulation of a single quarter. If we ran it again the results would be different, just like each quarter is different from previous ones. And this simulation is based on the parameters we used.

Let’s look first at the Won plus Commit forecast—the top of that grey section in the middle. The simulation starts with a modest forecast (the previous quarter carryover) and grows from there. This forecast (the top of the grey section) grossly under-predicts the outcome until very near the end of the quarter at which point it is pretty good.
When using highly predictive categories like Commit, classification models perform like our simulation, usually with higher variance. They grossly underestimate early in the quarter and are realistic near quarter end.
See how to sell more. Try Funnelcast. |
One approach to remedy the early under-forecasting is to expand the classification model to include the next most likely category—Best Case. Looking at the top of the yellow section, we see that adding Best Case increases the forecast. In this simulation, it's pretty good. The yellow (Won + Commit + Best Case) starts low, but is within +/- 10% for most of the quarter. While this simulated run is pretty good, it reflects what we see in real businesses. Classification forecasts may do very well in one quarter, but that is hard to repeat consistently.
You will only see this convergence to the final sales value if you have good data hygiene—declare the deals that slip as soon as you know. To avoid excessive carryover at the start of the next quarter, you need to not push deals to the next quarter unless they are also appropriately classified. Finally, you must filter your forecast to include only opportunities that are marked to close in the quarter. If you do these things, you can get classification forecasts that perform like our simulation—but with higher variance.
We are showing a single simulation of one quarter. We ran 1,000 simulations (Figure 3) to get a distribution of possible outcomes (expressed as a percent of the final sales for the quarter). The lines show the maximum, 90th percentile, mean, 10th percentile, and minimum. You won’t get to run 1,000 quarters, but we can learn from the simulation.

The distribution of Won + Commit forecasts reflects a conservative perspective. Even in the most optimistic case, the model under-forecasts until quarter end. Using the 10th to 90th percentiles, predictions start 80% of the time between 7% and 18% of the outcome—not helpful for forecasting the quarter’s sales. If you use a Commit classification model, it is often better to look at last quarter’s results to set expectations at the start of the new quarter.
The distribution of Won + Commit + Best Case forecasts (Figure 4) are more optimistic. The forecast is pretty good for the second half of the quarter, but still under-forecasting for the first half. If your business is like the settings in our simulation, then 80% of the time, if you start with a forecast of 100, you will end between 222 (100/45%) and 154 (100/65%).
It’s tempting to adjust forecasts for these errors. But you can’t do that. Our results are unique to the simulation settings we used. You won’t know your distribution of possible forecasts. So, this simulation tells us more about the best accuracy we can expect from a classification forecast. You can’t avoid these limitations.
In practice we see higher volatility with classification models than shown here. This is due to end of quarter/month activity spikes, last minute changes in deal values, opportunities slipping into the next quarter or pulled into this quarter at the last minute, and other factors not reflected in the simulation.

How close you come to your final figure is a function of how good your classification calls are and how far in advance you can make those calls. Given good data hygiene, and some combination of enough transaction volume and consistency of deal sizes, it is possible to get usable classification forecasts. Some businesses have these characteristics. In our experience, however, classification models are most useful for aligning resources, building a priority list for sales management, and for facilitating account reviews.
Classification models are commonly used because they are so easy to understand, and they are useful for filtering which opportunities you should pay attention to. But for most businesses, they are too volatile and inaccurate to rely on until the end of a quarter—when you least need it. More important, classification forecasts are limited in other ways:
They are often used as a way to hold people accountable. While this may appear to be useful, it thwarts the value. You will get a very accurate Commit predictor, a few days before deals close.
They can consume a lot of management cycles because they are often produced at different levels of the sales team to produce different views.
They can turn managers into zero-value-add data aggregators, instead of helping salespeople close more, they spend all their time updating the classifications.
If you want to improve your sales forecasts and you have sufficient transactional volume, consider using a probability-weighted approach. There’s no need for Funnelcast, or for a black-box/AI-based forecasting application. Start by defining the period for which Probability applies. The probability to win this quarter? Or for some other period. Given a clear definition of the period, you can build better forecasts for that period. This is a simple Salesforce report. And if you do this, you will improve your experience with Funnelcast when you are ready. That said, there are sales planning and optimization reasons for you to consider getting started with Funnelcast before you try to improve your forecasts.
[1] For geeks only: Our simulation randomly selects opportunity values from six gaussian distributions with means ranging from $100K to $3M and highly weighted towards lower values. This type of multimoded distribution of transaction values is common in B2B sales. The daily arrival rate for Best Case opportunities is Poisson distributed with a mean of 3 opportunities/day. The expected time to close is Poisson distributed with a 45 day mean. Best Case opportunities transition to Commit with mean time to close of 10 days (Poisson distributed). Predictive accuracy is 70% for Best Case, 95% for Commit. Opportunity close dates are known (and do not change) upon entering upon entering the forecast.
Comments